Inserting Data
Basic Example
You can use the familiar INSERT INTO TABLE command with ClickHouse. Let's insert some data into the table that we created in the start guide "Creating Tables in ClickHouse".
INSERT INTO helloworld.my_first_table (user_id, message, timestamp, metric) VALUES
(101, 'Hello, ClickHouse!', now(), -1.0 ),
(102, 'Insert a lot of rows per batch', yesterday(), 1.41421 ),
(102, 'Sort your data based on your commonly-used queries', today(), 2.718 ),
(101, 'Granules are the smallest chunks of data read', now() + 5, 3.14159 )
To verify that worked, we'll run the following SELECT query:
SELECT * FROM helloworld.my_first_table
Which returns:
user_id message timestamp metric
101 Hello, ClickHouse! 2024-11-13 20:01:22 -1
101 Granules are the smallest chunks of data read 2024-11-13 20:01:27 3.14159
102 Insert a lot of rows per batch 2024-11-12 00:00:00 1.41421
102 Sort your data based on your commonly-used queries 2024-11-13 00:00:00 2.718
Inserting into ClickHouse vs. OLTP Databases
As an OLAP (Online Analytical Processing) database, ClickHouse is optimized for high performance and scalability, allowing potentially millions of rows to be inserted per second. This is achieved through a combination of a highly parallelized architecture and efficient column-oriented compression, but with compromises on immediate consistency. More specifically, ClickHouse is optimized for append-only operations and offers only eventual consistency guarantees.
In contrast, OLTP databases such as Postgres are specifically optimized for transactional inserts with full ACID compliance, ensuring strong consistency and reliability guarantees. PostgreSQL uses MVCC (Multi-Version Concurrency Control) to handle concurrent transactions, which involves maintaining multiple versions of the data. These transactions can potentially involve a small number of rows at a time, with considerable overhead incurred due to the reliability guarantees limiting insert performance.
To achieve high insert performance while maintaining strong consistency guarantees, users should adhere to the simple rules described below when inserting data into ClickHouse. Following these rules will help to avoid issues users commonly encounter the first time they use ClickHouse, and try to replicate an insert strategy that works for OLTP databases.
Best Practices for Inserts
Insert in large batch sizes
By default, each insert sent to ClickHouse causes ClickHouse to immediately create a part of storage containing the data from the insert together with other metadata that needs to be stored. Therefore, sending a smaller amount of inserts that each contain more data, compared to sending a larger amount of inserts that each contain less data, will reduce the number of writes required. Generally, we recommend inserting data in fairly large batches of at least 1,000 rows at a time, and ideally between 10,000 to 100,000 rows. (Further details here).
If large batches are not possible, use asynchronous inserts described below.
Ensure consistent batches for idempotent retries
By default, inserts into ClickHouse are synchronous and idempotent (i.e. performing the same insert operation multiple times has the same effect as performing it once). For tables of the MergeTree engine family, ClickHouse will, by default, automatically deduplicate inserts.
This means inserts remain resilient in the following cases:
- If the node receiving the data has issues, the insert query will time out (or give a more specific error) and not get an acknowledgment.
- If the data got written by the node but the acknowledgement can't be returned to the sender of the query because of network interruptions, the sender will either get a time-out or a network error.
From the client's perspective, (i) and (ii) can be hard to distinguish. However, in both cases, the unacknowledged insert can just be immediately retried. As long as the retried insert query contains the same data in the same order, ClickHouse will automatically ignore the retried insert if the (unacknowledged) original insert succeeded.
Insert to a MergeTree table or a distributed table
We recommend inserting directly into a MergeTree (or Replicated table), balancing the requests across a set of nodes if the data is sharded, and setting internal_replication=true.
This will leave ClickHouse to replicate the data to any available replica shards and ensure the data is eventually consistent.
If this client side load balancing is inconvenient then users can insert via a distributed table which will then distribute writes across the nodes. Again, it is advised to set internal_replication=true.
It should be noted however that this approach is a little less performant as writes have to be made locally on the node with the distributed table and then sent to the shards.
Use asynchronous inserts for small batches
There are scenarios where client-side batching is not feasible e.g. an observability use case with 100s or 1000s of single-purpose agents sending logs, metrics, traces, etc. In this scenario real-time transport of that data is key to detect issues and anomalies as quickly as possible. Furthermore, there is a risk of event spikes in the observed systems, which could potentially cause large memory spikes and related issues when trying to buffer observability data client-side. If large batches cannot be inserted, users can delegate batching to ClickHouse using asynchronous inserts.
With asynchronous inserts, data is inserted into a buffer first and then written to the database storage later in 3 steps, as illustrated by the diagram below:
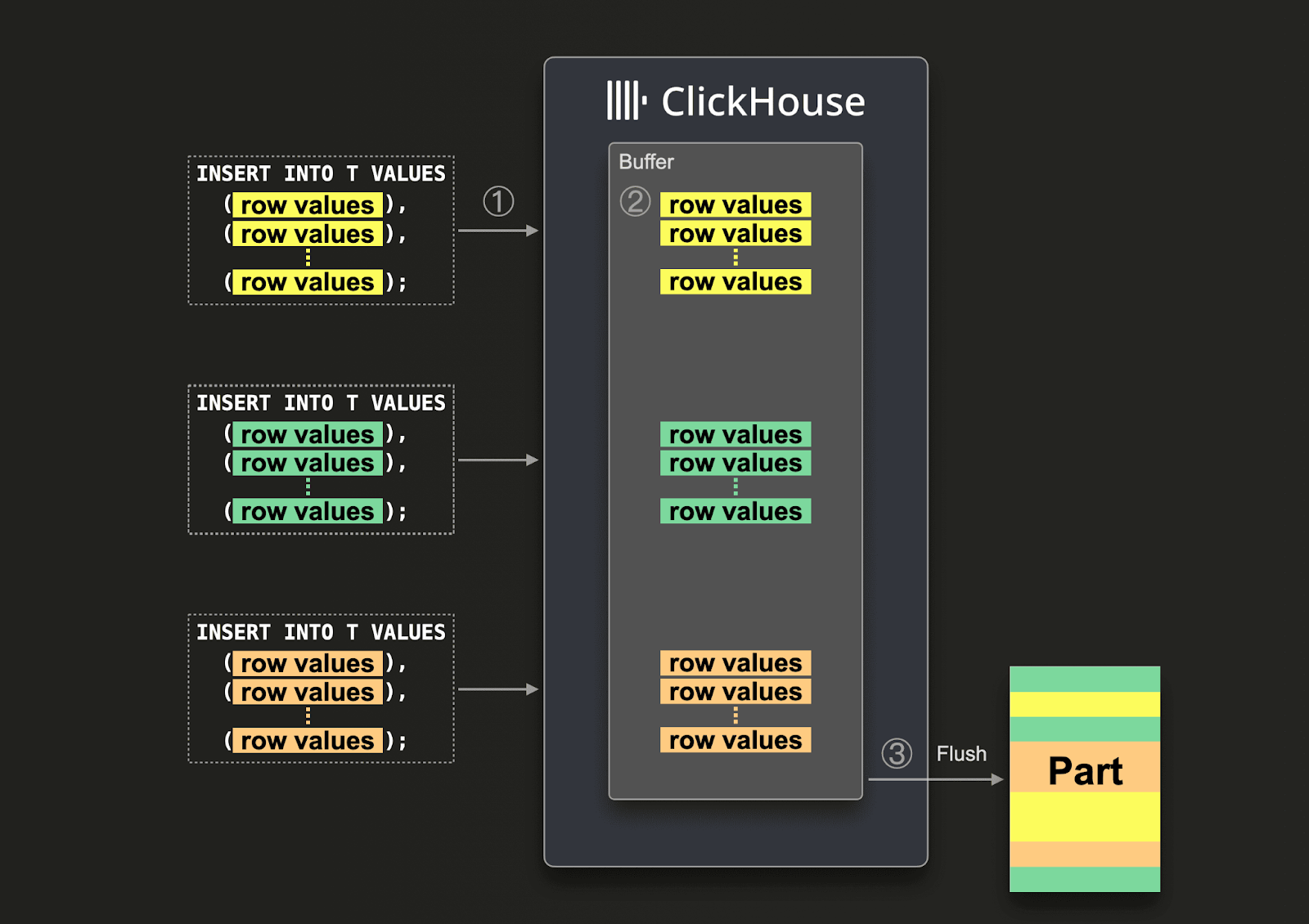
With asynchronous inserts enabled, ClickHouse:
(1) receives an insert query asynchronously.
(2) writes the query's data into an in-memory buffer first.
(3) sorts and writes the data as a part to the database storage, only when the next buffer flush takes place.
Before the buffer gets flushed, the data of other asynchronous insert queries from the same or other clients can be collected in the buffer. The part created from the buffer flush will potentially contain the data from several asynchronous insert queries. Generally, these mechanics shift the batching of data from the client side to the server side (ClickHouse instance).
Use official ClickHouse clients
ClickHouse has clients in the most popular programming languages. These are optimized to ensure that inserts are performed correctly and natively support asynchronous inserts either directly as in e.g. the Go client, or indirectly when enabled in the query, user or connection level settings.
See Clients and Drivers for a full list of available ClickHouse clients and drivers.
Prefer the Native format
ClickHouse supports many input formats at insert (and query) time. This is a significant difference with OLTP databases and makes loading data from external sources much easier - especially when coupled with table functions and the ability to load data from files on disk. These formats are ideal for ad hoc data loading and data engineering tasks.
For applications looking to achieve optimal insert performance, users should insert using the Native format. This is supported by most clients (such as Go and Python) and ensures the server has to do a minimal amount of work since this format is already column-oriented. By doing so the responsibility for converting data into a column-oriented format is placed on the client side. This is important for scaling inserts efficiently.
Alternatively, users can use RowBinary format (as used by the Java client) if a row format is preferred - this is typically easier to write than the Native format. This is more efficient, in terms of compression, network overhead, and processing on the server, than alternative row formats such as JSON. The JSONEachRow format can be considered for users with lower write throughputs looking to integrate quickly. Users should be aware this format will incur a CPU overhead in ClickHouse for parsing.
Use the HTTP interface
Unlike many traditional databases, ClickHouse supports an HTTP interface. Users can use this for both inserting and querying data, using any of the above formats. This is often preferable to ClickHouse’s native protocol as it allows traffic to be easily switched with load balancers. We expect small differences in insert performance with the native protocol, which incurs a little less overhead. Existing clients use either of these protocols ( in some cases both e.g. the Go client). The native protocol does allow query progress to be easily tracked.
See HTTP Interface for further details.
Loading data from Postgres
For loading data from Postgres, users can use:
- using ClickPipes, the managed integration service for ClickHouse Cloud - now in Private Preview. Please sign up here
PeerDB by ClickHouse, an ETL tool specifically designed for PostgreSQL database replication to both self-hosted ClickHouse and ClickHouse Cloud.- PeerDB is now available natively in ClickHouse Cloud - Blazing-fast Postgres to ClickHouse CDC with our new ClickPipe connector - now in Private Preview. Please sign up here
- The Postgres Table Function to read data directly. This is typically appropriate for if batch replication based on a known watermark, e.g. a timestamp. is sufficient or if it's a once-off migration. This approach can scale to 10's of millions of rows. Users looking to migrate larger datasets should consider multiple requests, each dealing with a chunk of the data. Staging tables can be used for each chunk prior to its partitions being moved to a final table. This allows failed requests to be retried. For further details on this bulk-loading strategy, see here.
- Data can be exported from Postgres in CSV format. This can then be inserted into ClickHouse from either local files or via object storage using table functions.
If you need help inserting large datasets or encounter any errors when importing data into ClickHouse Cloud, please contact us at support@clickhouse.com and we can assist.